# Stable Diffusion 2.0



This repository contains [Stable Diffusion](https://github.com/CompVis/stable-diffusion) models trained from scratch and will be continuously updated with
new checkpoints. The following list provides an overview of all currently available models. More coming soon.
## News
**November 2022**
- New stable diffusion model (_Stable Diffusion 2.0-v_) at 768x768 resolution. Same number of parameters in the U-Net as 1.5, but uses [OpenCLIP-ViT/H](https://github.com/mlfoundations/open_clip) as the text encoder and is trained from scratch. _SD 2.0-v_ is a so-called [v-prediction](https://arxiv.org/abs/2202.00512) model.
- The above model is finetuned from _SD 2.0-base_, which was trained as a standard noise-prediction model on 512x512 images and is also made available.
- Added a [x4 upscaling latent text-guided diffusion model](#image-upscaling-with-stable-diffusion).
- New [depth-guided stable diffusion model](#depth-conditional-stable-diffusion), finetuned from _SD 2.0-base_. The model is conditioned on monocular depth estimates inferred via [MiDaS](https://github.com/isl-org/MiDaS) and can be used for structure-preserving img2img and shape-conditional synthesis.

- A [text-guided inpainting model](#image-inpainting-with-stable-diffusion), finetuned from SD _2.0-base_.
We follow the [original repository](https://github.com/CompVis/stable-diffusion) and provide basic inference scripts to sample from the models.
________________
*The original Stable Diffusion model was created in a collaboration with [CompVis](https://arxiv.org/abs/2202.00512) and [RunwayML](https://runwayml.com/) and builds upon the work:*
[**High-Resolution Image Synthesis with Latent Diffusion Models**](https://ommer-lab.com/research/latent-diffusion-models/)
[Robin Rombach](https://github.com/rromb)\*,
[Andreas Blattmann](https://github.com/ablattmann)\*,
[Dominik Lorenz](https://github.com/qp-qp)\,
[Patrick Esser](https://github.com/pesser),
[Björn Ommer](https://hci.iwr.uni-heidelberg.de/Staff/bommer)
_[CVPR '22 Oral](https://openaccess.thecvf.com/content/CVPR2022/html/Rombach_High-Resolution_Image_Synthesis_With_Latent_Diffusion_Models_CVPR_2022_paper.html) |
[GitHub](https://github.com/CompVis/latent-diffusion) | [arXiv](https://arxiv.org/abs/2112.10752) | [Project page](https://ommer-lab.com/research/latent-diffusion-models/)_
and [many others](#shout-outs).
Stable Diffusion is a latent text-to-image diffusion model.
________________________________
## Requirements
You can update an existing [latent diffusion](https://github.com/CompVis/latent-diffusion) environment by running
```
conda install pytorch==1.12.1 torchvision==0.13.1 -c pytorch
pip install transformers==4.19.2 diffusers invisible-watermark
pip install -e .
```
#### xformers efficient attention
For more efficiency and speed on GPUs,
we highly recommended installing the [xformers](https://github.com/facebookresearch/xformers)
library.
Tested on A100 with CUDA 11.4.
Installation needs a somewhat recent version of nvcc and gcc/g++, obtain those, e.g., via
```commandline
export CUDA_HOME=/usr/local/cuda-11.4
conda install -c nvidia/label/cuda-11.4.0 cuda-nvcc
conda install -c conda-forge gcc
conda install -c conda-forge gxx_linux-64=9.5.0
```
Then, run the following (compiling takes up to 30 min).
```commandline
cd ..
git clone https://github.com/facebookresearch/xformers.git
cd xformers
git submodule update --init --recursive
pip install -r requirements.txt
pip install -e .
cd ../stablediffusion
```
Upon successful installation, the code will automatically default to [memory efficient attention](https://github.com/facebookresearch/xformers)
for the self- and cross-attention layers in the U-Net and autoencoder.
## General Disclaimer
Stable Diffusion models are general text-to-image diffusion models and therefore mirror biases and (mis-)conceptions that are present
in their training data. Although efforts were made to reduce the inclusion of explicit pornographic material, **we do not recommend using the provided weights for services or products without additional safety mechanisms and considerations.
The weights are research artifacts and should be treated as such.**
Details on the training procedure and data, as well as the intended use of the model can be found in the corresponding [model card](https://huggingface.co/stabilityai/stable-diffusion-2).
The weights are available via [the StabilityAI organization at Hugging Face](https://huggingface.co/StabilityAI) under the [CreativeML Open RAIL++-M License](LICENSE-MODEL).
## Stable Diffusion v2.0
Stable Diffusion v2.0 refers to a specific configuration of the model
architecture that uses a downsampling-factor 8 autoencoder with an 865M UNet
and OpenCLIP ViT-H/14 text encoder for the diffusion model. The _SD 2.0-v_ model produces 768x768 px outputs.
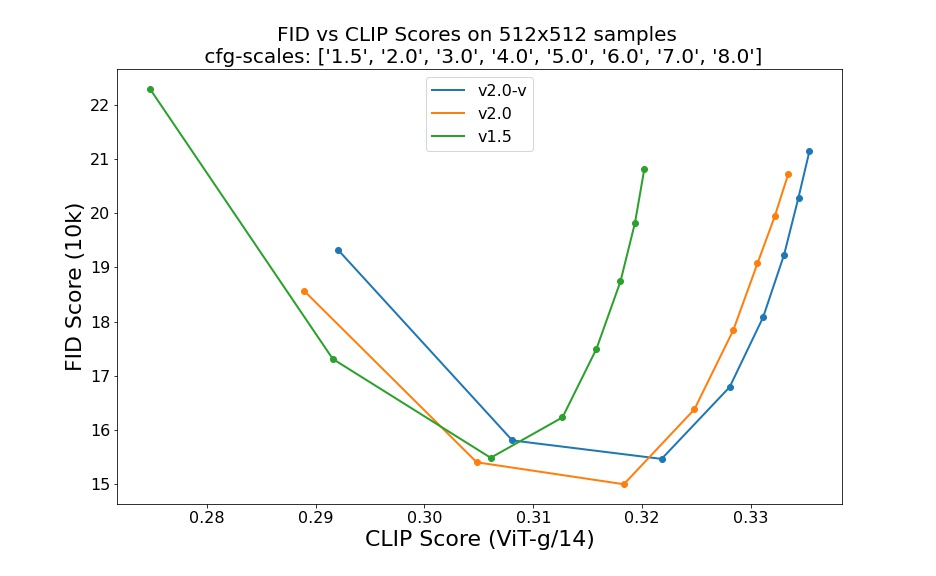
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 DDIM sampling steps show the relative improvements of the checkpoints:
### Text-to-Image


Stable Diffusion 2.0 is a latent diffusion model conditioned on the penultimate text embeddings of a CLIP ViT-H/14 text encoder.
We provide a [reference script for sampling](#reference-sampling-script).
#### Reference Sampling Script
This script incorporates an [invisible watermarking](https://github.com/ShieldMnt/invisible-watermark) of the outputs, to help viewers [identify the images as machine-generated](scripts/tests/test_watermark.py).
We provide the configs for the _SD2.0-v_ (768px) and _SD2.0-base_ (512px) model.
First, download the weights for [_SD2.0-v_](https://huggingface.co/stabilityai/stable-diffusion-2) and [_SD2.0-base_](https://huggingface.co/stabilityai/stable-diffusion-2-base).
To sample from the _SD2.0-v_ model, run the following:
```
python scripts/txt2img.py --prompt "a professional photograph of an astronaut riding a horse" --ckpt --config configs/stable-diffusion/v2-inference-v.yaml --H 768 --W 768
```
or try out the Web Demo: [](https://huggingface.co/spaces/stabilityai/stable-diffusion).
To sample from the base model, use
```
python scripts/txt2img.py --prompt "a professional photograph of an astronaut riding a horse" --ckpt --config
```
By default, this uses the [DDIM sampler](https://arxiv.org/abs/2010.02502), and renders images of size 768x768 (which it was trained on) in 50 steps.
Empirically, the v-models can be sampled with higher guidance scales.
Note: The inference config for all model versions is designed to be used with EMA-only checkpoints.
For this reason `use_ema=False` is set in the configuration, otherwise the code will try to switch from
non-EMA to EMA weights.
### Image Modification with Stable Diffusion

#### Depth-Conditional Stable Diffusion
To augment the well-established [img2img](https://github.com/CompVis/stable-diffusion#image-modification-with-stable-diffusion) functionality of Stable Diffusion, we provide a _shape-preserving_ stable diffusion model.
Note that the original method for image modification introduces significant semantic changes w.r.t. the initial image.
If that is not desired, download our [depth-conditional stable diffusion](https://huggingface.co/stabilityai/stable-diffusion-2-depth) model and the `dpt_hybrid` MiDaS [model weights](https://github.com/intel-isl/DPT/releases/download/1_0/dpt_hybrid-midas-501f0c75.pt), place the latter in a folder `midas_models` and sample via
```
python scripts/gradio/depth2img.py configs/stable-diffusion/v2-midas-inference.yaml
```
or
```
streamlit run scripts/streamlit/depth2img.py configs/stable-diffusion/v2-midas-inference.yaml
```
This method can be used on the samples of the base model itself.
For example, take [this sample](assets/stable-samples/depth2img/old_man.png) generated by an anonymous discord user.
Using the [gradio](https://gradio.app) or [streamlit](https://streamlit.io/) script `depth2img.py`, the MiDaS model first infers a monocular depth estimate given this input,
and the diffusion model is then conditioned on the (relative) depth output.
depth2image

This model is particularly useful for a photorealistic style; see the [examples](assets/stable-samples/depth2img).
For a maximum strength of 1.0, the model removes all pixel-based information and only relies on the text prompt and the inferred monocular depth estimate.

#### Classic Img2Img
For running the "classic" img2img, use
```
python scripts/img2img.py --prompt "A fantasy landscape, trending on artstation" --init-img --strength 0.8 --ckpt
```
and adapt the checkpoint and config paths accordingly.
### Image Upscaling with Stable Diffusion

After [downloading the weights](https://huggingface.co/stabilityai/stable-diffusion-x4-upscaler), run
```
python scripts/gradio/superresolution.py configs/stable-diffusion/x4-upscaling.yaml
```
or
```
streamlit run scripts/streamlit/superresolution.py -- configs/stable-diffusion/x4-upscaling.yaml
```
for a Gradio or Streamlit demo of the text-guided x4 superresolution model.
This model can be used both on real inputs and on synthesized examples. For the latter, we recommend setting a higher
`noise_level`, e.g. `noise_level=100`.
### Image Inpainting with Stable Diffusion

[Download the SD 2.0-inpainting checkpoint](https://huggingface.co/stabilityai/stable-diffusion-2-inpainting) and run
```
python scripts/gradio/inpainting.py configs/stable-diffusion/v2-inpainting-inference.yaml
```
or
```
streamlit run scripts/streamlit/inpainting.py -- configs/stable-diffusion/v2-inpainting-inference.yaml
```
for a Gradio or Streamlit demo of the inpainting model.
This scripts adds invisible watermarking to the demo in the [RunwayML](https://github.com/runwayml/stable-diffusion/blob/main/scripts/inpaint_st.py) repository, but both should work interchangeably with the checkpoints/configs.
## Shout-Outs
- Thanks to [Hugging Face](https://huggingface.co/) and in particular [Apolinário](https://github.com/apolinario) for support with our model releases!
- Stable Diffusion would not be possible without [LAION](https://laion.ai/) and their efforts to create open, large-scale datasets.
- The [DeepFloyd team](https://twitter.com/deepfloydai) at Stability AI, for creating the subset of [LAION-5B](https://laion.ai/blog/laion-5b/) dataset used to train the model.
- Stable Diffusion 2.0 uses [OpenCLIP](https://laion.ai/blog/large-openclip/), trained by [Romain Beaumont](https://github.com/rom1504).
- Our codebase for the diffusion models builds heavily on [OpenAI's ADM codebase](https://github.com/openai/guided-diffusion)
and [https://github.com/lucidrains/denoising-diffusion-pytorch](https://github.com/lucidrains/denoising-diffusion-pytorch).
Thanks for open-sourcing!
- [CompVis](https://github.com/CompVis/stable-diffusion) initial stable diffusion release
- [Patrick](https://github.com/pesser)'s [implementation](https://github.com/runwayml/stable-diffusion/blob/main/scripts/inpaint_st.py) of the streamlit demo for inpainting.
- `img2img` is an application of [SDEdit](https://arxiv.org/abs/2108.01073) by [Chenlin Meng](https://cs.stanford.edu/~chenlin/) from the [Stanford AI Lab](https://cs.stanford.edu/~ermon/website/).
- [Kat's implementation]((https://github.com/CompVis/latent-diffusion/pull/51)) of the [PLMS](https://arxiv.org/abs/2202.09778) sampler, and [more](https://github.com/crowsonkb/k-diffusion).
- [DPMSolver](https://arxiv.org/abs/2206.00927) [integration](https://github.com/CompVis/stable-diffusion/pull/440) by [Cheng Lu](https://github.com/LuChengTHU).
- Facebook's [xformers](https://github.com/facebookresearch/xformers) for efficient attention computation.
- [MiDaS](https://github.com/isl-org/MiDaS) for monocular depth estimation.
## License
The code in this repository is released under the MIT License.
The weights are available via [the StabilityAI organization at Hugging Face](https://huggingface.co/StabilityAI), and released under the [CreativeML Open RAIL++-M License](LICENSE-MODEL) License.
## BibTeX
```
@misc{rombach2021highresolution,
title={High-Resolution Image Synthesis with Latent Diffusion Models},
author={Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Björn Ommer},
year={2021},
eprint={2112.10752},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```